机器学习概述
# 深度学习、机器学习和模式识别
- 模式识别(Pattern recognition)
- 机器学习(machine learning)
- 深度学习(deep learning)
代表三种不同的思想流派。
模式识别是最古老的(作为一个术语而言,可以说是很过时的)。
机器学习是最基础的(当下初创公司和研究实验室的热点领域之一)。
深度学习是非常崭新和有影响力的前沿领域,我们甚至不会去思考后深度学习时代。
# 模式识别:智能程序的诞生
模式识别是70年代和80年代非常流行的一个术语。它强调的是如何让一个计算机程序去做一些看起来很“智能”的事情,例如识别“3”这个数字。而且在融入了很多的智慧和直觉后,人们也的确构建了这样的一个程序。例如,区分“3”和“B”或者“3”和“8”。早在以前,大家也不会去关心你是怎么实现的,只要这个机器不是由人躲在盒子里面伪装的就好(图2)。不过,如果你的算法对图像应用了一些像滤波器、边缘检测和形态学处理等等高大上的技术后,模式识别社区肯定就会对它感兴趣。光学字符识别就是从这个社区诞生的。因此,把模式识别称为70年代,80年代和90年代初的“智能”信号处理是合适的。决策树、启发式和二次判别分析等全部诞生于这个时代。而且,在这个时代,模式识别也成为了计算机科学领域的小伙伴搞的东西,而不是电子工程。从这个时代诞生的模式识别领域最著名的书之一是由Duda & Hart执笔的“模式识别(Pattern Classification)”。对基础的研究者来说,仍然是一本不错的入门教材。不过对于里面的一些词汇就不要太纠结了,因为这本书已经有一定的年代了,词汇会有点过时。
# 机器学习:从样本中学习的智能程序
在90年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据(可以通过廉价劳动力采集获得)去替换专家(具有很多图像方面知识的人)。因此,我们搜集大量的人脸和非人脸图像,再选择一个算法,然后冲着咖啡、晒着太阳,等着计算机完成对这些图像的学习。这就是机器学习的思想。“机器学习”强调的是,在给计算机程序(或者机器)输入一些数据后,它必须做一些事情,那就是学习这些数据,而这个学习的步骤是明确的。相信我,就算计算机完成学习要耗上一天的时间,也会比你邀请你的研究伙伴来到你家然后专门手工得为这个任务设计一些分类规则要好。
在21世纪中期,机器学习成为了计算机科学领域一个重要的研究课题,计算机科学家们开始将这些想法应用到更大范围的问题上,不再限于识别字符、识别猫和狗或者识别图像中的某个目标等等这些问题。研究人员开始将机器学习应用到机器人(强化学习,操控,行动规划,抓取)、基因数据的分析和金融市场的预测中。另外,机器学习与图论的联姻也成就了一个新的课题—图模型。每一个机器人专家都“无奈地”成为了机器学习专家,同时,机器学习也迅速成为了众人渴望的必备技能之一。然而,“机器学习”这个概念对底层算法只字未提。我们已经看到凸优化、核方法、支持向量机和Boosting算法等都有各自辉煌的时期。再加上一些人工设计的特征,那在机器学习领域,我们就有了很多的方法,很多不同的思想流派,然而,对于一个新人来说,对特征和算法的选择依然一头雾水,没有清晰的指导原则。但,值得庆幸的是,这一切即将改变……
# 深度学习:一统江湖的架构
快进到今天,我们看到的是一个夺人眼球的技术—深度学习。而在深度学习的模型中,受宠爱最多的就是被用在大规模图像识别任务中的卷积神经网络(Convolutional Neural Nets,CNN),简称ConvNets。
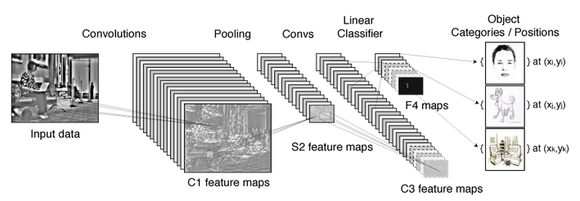
深度学习强调的是你使用的模型(例如深度卷积多层神经网络),模型中的参数通过从数据中学习获得。然而,深度学习也带来了一些其他需要考虑的问题。因为你面对的是一个高维的模型(即庞大的网络),所以你需要大量的数据(大数据)和强大的运算能力(图形处理器,GPU)才能优化这个模型。卷积被广泛用于深度学习(尤其是计算机视觉应用中),而且它的架构往往都是非浅层的。
如果你要学习Deep Learning,那就得先复习下一些线性代数的基本知识,当然了,也得有编程基础。我强烈推荐Andrej Karpathy的博文:“ 神经网络的黑客指南 ”。另外,作为学习的开端,可以选择一个不用卷积操作的应用问题,然后自己实现基于CPU的反向传播算法。
对于深度学习,还存在很多没有解决的问题。既没有完整的关于深度学习有效性的理论,也没有任何一本能超越机器学习实战经验的指南或者书。另外,深度学习不是万能的,它有足够的理由能日益流行,但始终无法接管整个世界。不过,只要你不断增加你的机器学习技能,你的饭碗无忧。但也不要对深度框架过于崇拜,不要害怕对这些框架进行裁剪和调整,以得到和你的学习算法能协同工作的软件框架。未来的Linux内核也许会在Caffe(一个非常流行的深度学习框架)上运行,然而,伟大的产品总是需要伟大的愿景、领域的专业知识、市场的开发,和最重要的:人类的创造力。
# 机器学习 研究意义
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
# 机器学习 场景
- 例如:识别动物猫
- 模式识别(官方标准):人们通过大量的经验,得到结论,从而判断它就是猫。
- 机器学习(数据学习):人们通过阅读进行学习,观察它会叫、小眼睛、两只耳朵、四条腿、一条尾巴,得到结论,从而判断它就是猫。
- 深度学习(深入数据):人们通过深入了解它,发现它会’喵喵’的叫、与同类的猫科动物很类似,得到结论,从而判断它就是猫。(深度学习常用领域:语音识别、图像识别)
- 模式识别(pattern recognition): 模式识别是最古老的(作为一个术语而言,可以说是很过时的)。
- 我们把环境与客体统称为“模式”,识别是对模式的一种认知,是如何让一个计算机程序去做一些看起来很“智能”的事情。
- 通过融于智慧和直觉后,通过构建程序,识别一些事物,而不是人,例如: 识别数字。
- 机器学习(machine learning): 机器学习是最基础的(当下初创公司和研究实验室的热点领域之一)。
- 在90年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据(可以通过廉价劳动力采集获得)去替换专家(具有很多图像方面知识的人)。
- “机器学习”强调的是,在给计算机程序(或者机器)输入一些数据后,它必须做一些事情,那就是学习这些数据,而这个学习的步骤是明确的。
- 机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身性能的学科。
- 深度学习(deep learning): 深度学习是非常崭新和有影响力的前沿领域,我们甚至不会去思考-后深度学习时代。
- 深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
按照任务是否需要和环境进行交互获得经验
- 监督学习
- 根据标签存在与否进行分类
- 每一个训练数据都存在对应的标签——传统的监督学习
- 支持向量机
- 人工神经网络
- 深度神经网络
- 不存在标签——非监督学习
- 聚类
- EM算法
- 主成分分析
- 半监督学习
- 少量标注数据+大量未标注数据→更好的机器学习算法
- 每一个训练数据都存在对应的标签——传统的监督学习
- 基于标签的固有属性
- 分类——标签是离散值
- 人脸识别
- 回归——标签是连续值
- 预测房价
- 分类——标签是离散值
- 根据标签存在与否进行分类
- 强化学习
- 自动驾驶
# 机器学习 工具
# Python语言
- 可执行伪代码
- Python比较流行:使用广泛、代码范例多、丰富模块库,开发周期短
- Python语言的特色:清晰简练、易于理解
- Python语言的缺点:唯一不足的是性能问题
- Python相关的库
- 科学函数库:
SciPy、NumPy(底层语言:C和Fortran) - 绘图工具库:
Matplotlib - 数据分析库
Pandas
- 科学函数库:
# 数学工具
- Matlab

没有放之四海皆准的算法

